发生雪崩效应后,业务场景下的应对策略
背景
QE是一个查询代理服务。它包含实时查询(redis)、历史查询(tsdb)和 数据库查询(cube)。
其中,实时查询的特点是:
- 查询比较重要
- 查询量小
- 响应时间短
- 查询频率相对稳定
而历史查询的特点是:
- 查询不重要,可以失败
- 查询时间长,返回结果大
- 有突发查询请求发生情况
对于历史查询,当查询响应时间长,请求量大时,会耗尽tomcat线程池,从而导致重要的实时查询被阻塞,从而导致QE整体服务不可用。
解决方案
上面的现象就是典型的雪崩效应,当某一处故障时,发生的连环反应。
限流
限流有两种方式限流,一种是并发限流,防止查询时间长,并发线程大而导致tomcat线程池占满。
另一种是qps限流。每秒限制查询请求数,防止请求过于频繁,从而占用更多的资源。
当前QE的所有查询,都公用同一个tomcat线程池,可以为它们做资源隔离。例如做线程隔离。
为历史查询做独立的线程池,为它配置上限。当线程并发达到最大时,拒绝后来的请求。(快速失败)
从而来达到保护其它接口的效果。
线程隔离的缺点是,线程会频繁进行上下文切换。比较占用cpu。优点是,能够支持一定的并发量,而且对代码没有侵入。
在线程隔离的基础上,还可以使用信号量来进行流控。维护一个全局变量,当发生一次请求时,变量+1,当结束请求后,变量-1。当变量值达到最大时,拒绝访问。它可以明确限制请求的qps,防止大量的请求撑爆内存,或者给tsdb带来较大的压力。
熔断
当tsdb不可用,或频繁返回失败时,触发熔断。
在某个时间窗口(例如10s),如果错误率达到70%,则不再响应后续的请求。让尽快失败。
该操作可以解决,hbase宕机或tsdb请求很大时,不再给tsdb压力。
再或者,有频繁的错误请求进来时,不再继续执行该错误请求,提前抛出异常。(通常发生在补数据情况下)
当补数据时错误的请求发生时,为了不影响正常历史数据查询,通过请求来源来进行熔断。
即:当发生在补数据时,请求失败率如果达到70%,则来源为“补数据”的请求直接返回失败。而来源为web-ui的请求,则不进行熔断。
QE目前遇到的三大问题
- 频繁并长时间的tsdb查询,耗尽线程池,导致realtime查询受影响
- 大量错误查询导致hbase异常崩溃
- 大范围查询导致jvm内存OOM
实现设计
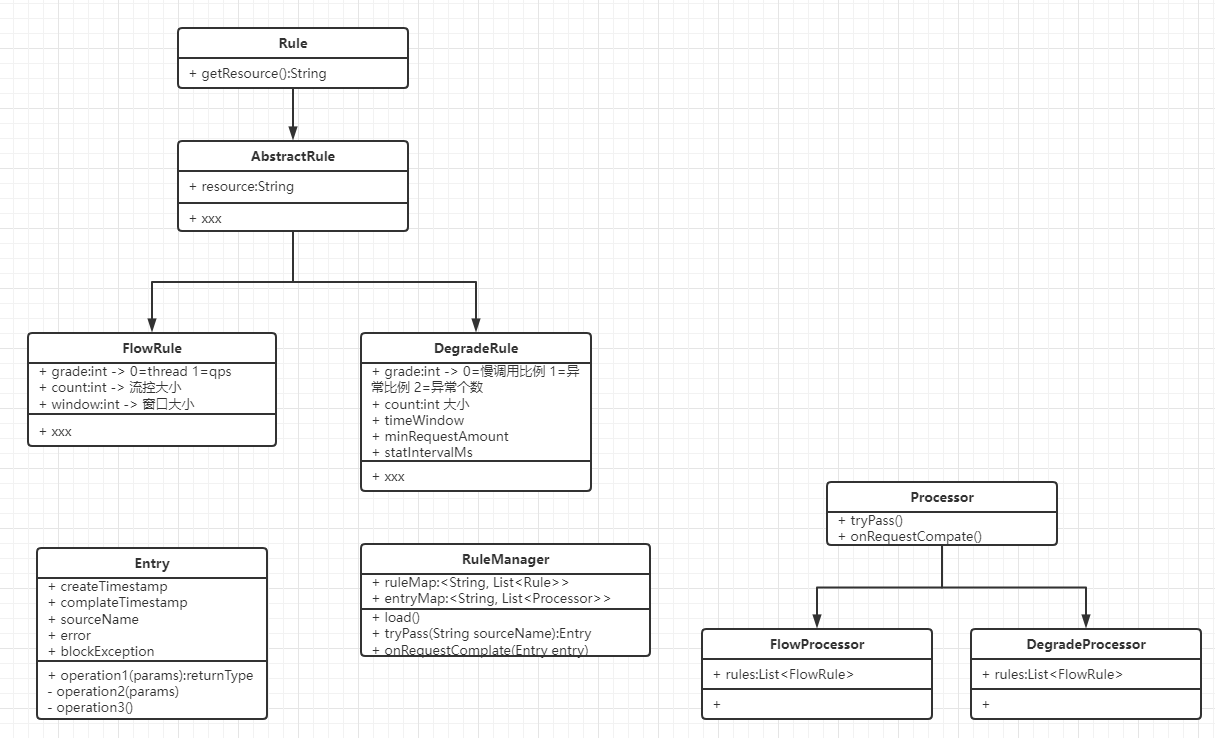
建议配置:
- 全局配置
- 设定全局单位时间内最大流量
- 设定最大并发线程数
- 子配置
- 按查询设定单位时间内最大流量
- 设定最大并发线程数
- 设定发生错误时的error熔断
当一个请求进来时,优先检查全局配置是否被限制,如果已达到全局配置,则进行限流。
当全局检查放行时,以查询的 请求体取hash 作为查询key,对该 key 进行熔断/限流检查,如果通过,则放行,否则抛BlockException,进行阻塞。
全局配置的目的是为了防止在商户增多时,整体流量或并发增大,导致其它查询接口被堵塞。
子配置的目的是为了防止,某个错误的请求发生时,不影响其它正常的请求。
Q&A
rt和tsdb做完全的线程隔离,出现浪费怎么办?
支持上下限配置。
例如:
配置A –> 总共300个线程池,rt配置100,tsdb配置200,这种配置是完全隔离,互不影响。
配置B –> 总共300个线程池,rt最小配置50,最大配置150,平均100;tsdb最小配置150,最大配置250,平均200。当tsdb已经使用了200个线程后,如果rt线程使用未达到最小值(50),则tsdb允许继续申请,直到无法申请或达到最大值。当tsdb超额申请后,rt请求突增,rt线程使用了50+,tsdb释放后,不再继续申请,给rt使用。
这种配置属于动态配置,资源充分利用的同时避免被tsdb完全占用
当tsdb查询因为线程不足被限流时,该如何做?
触发限流后,直接抛出异常。
大家关心的查询不能失败、不能丢失等情况。在我们不做限流这个功能时,也是会出现的现象。
大家疑惑的,被限流后,能否进行排队处理。我认为没有必要。排队只是把立马告知用户的时间延迟了而已。
那么限流被触发后,只能眼睁睁看着后续的请求都被拒绝吗?
有了限流策略,就必须要增加监控指标,有了监控指标,就可以做动态扩缩容。
例如:当持续1分钟都触发了限流,则进行动态扩容。当持续10分钟都没有达到最小限流配置项,则进行缩容。
哪些场景会触发熔断?
时间窗口内,达到错误率
时间窗口内,达到错误数
时间窗口内,慢查询率
时间窗口内,慢查询数
触发熔断后的策略是什么?
直接拒绝。
一开始请求错误,当我的请求正确以后,还失败吗?
在一个时间窗口内失败,下个时间窗口内,会进行试探,最小试探次数可配置,在最小试探次数内,错误率/数如果降低,则正常放行,否则继续熔断。
对于batch_query,如果一个batch里面,一部分错误,一部分正确,该如何处理?
熔断是基于单个请求体上的。batch_query请求,触发熔断的请求,会返回null,未触发熔断的请求,会正常查询。