HBase采坑集:三、迁移过程中出现的重大线上事故
上一篇记录了在进行bulkload编码时遇到的坑,这一篇记录一下,实际执行过程中遇到的坑。
采坑集
采坑1——单次load太多hfile后,hmaster飘红
现象
单次load了太多的hfile,每个region接近100个hfile,导致hmaster飘红,飘红原因是:索引文件太多。
解决方案
根据提示原因,可以看出,每个hfile文件load在hbase后,都会在master上建立一个索引,过多的索引文件,会导致master异常。因此,在load数据时,尽可能少量load。确保master不宕机。
采坑2——load数据以后,进行查询,很慢
现象
刚开始load数据时,对查询基本无影响,因为每个Region中,hfile比较小。
当每个Region下,hfile增大到5G以上,查询变得异常慢。
主要原因在于,新load进来的hfile,是通过append的方式追加起来的,它是没有经过排序,无索引的。
解决方案
当load完成后,执行一次major compaction。通过major compaction,可以让无索引的region建立索引。
major compaction是一个比较慢的过程。
建议load历史数据前,不要开启业务访问。当全部load完成,major compaction做完以后再开启业务访问。
采坑3——在进行load时,压缩队列持续告警
现象
当load数据是,因为load量比较大,需要进行compaction,compact时间比较长,导致正常写入的数据flush以后,一直在compaction队列中排队。因此,压缩队列持续告警。
解决方案
- 每次load少一点
- load前,不要开启业务,等load结束后再开启
- 在新集群上做,尽量不要影响老集群
采坑4——当load太多时,大量region同时触发split,导致hmaster崩溃(线上重大事故)
现象
- 下午3点开始,HBase Master异常崩溃。

根据监控显示:master 内存溢出。
- 当再次尝试重启HMaster时,启动失败。

主要原因在于:HMaster在启动失败时,大量打内存堆栈日志,导致主节点磁盘空间不够。
- 释放磁盘空间后,再次启动HMaster,依然启动失败。
主要原因是,内存不足导致无法启动HMaster
将HMaster内存大小由1G调整为4G时,启动正常,但启动后不久,继续OOM
将内存大小调整为8G后,启动正常。
服务虽然启动了,但是在崩溃前一些split操作没有完成,导致启动后,HBase WEB-UI出现永久RIT
使用meta修复工具后,hbase恢复正常。但是,上一次的split依旧未解决,hdfs中存在着未split的引用。因为崩溃原因,该引用指向的文件无法找到。在进行compaction时,频繁出现FileNotFoundException
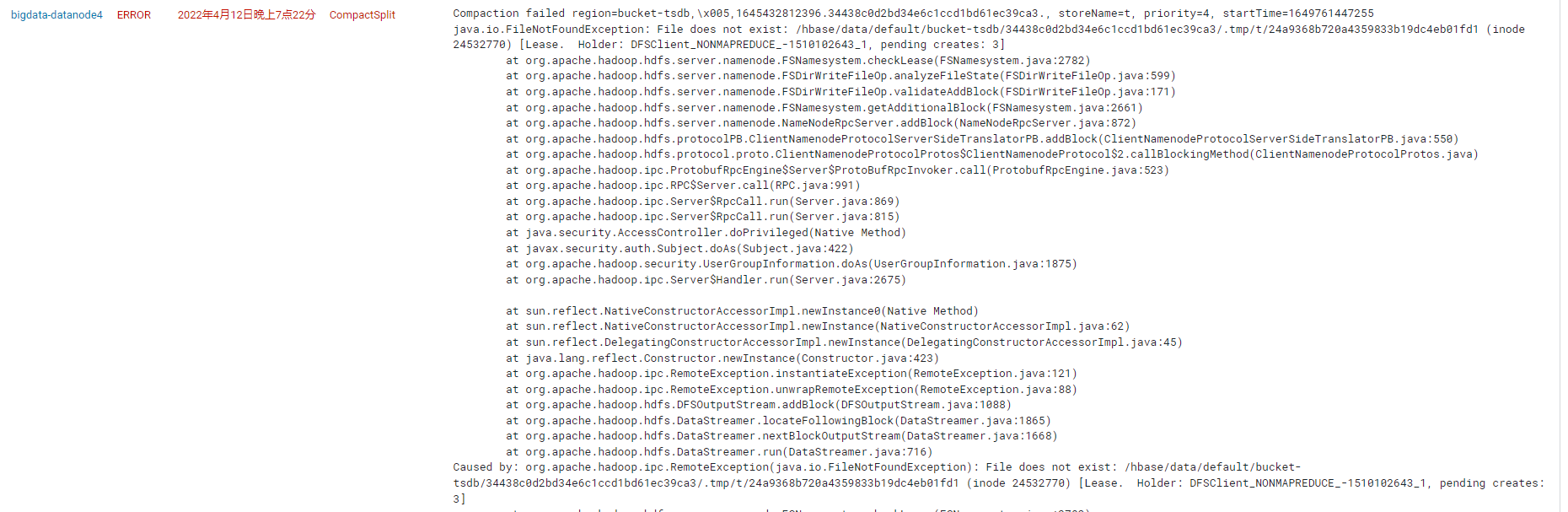
- 以上异常能虽然能正常写入,但无法正确的进行读和compaction
无法compaction,导致的后果是,hfile文件越来越多,当hfile文件达到一定值以后,就无法再进行写入。
- 4月13号早上9点多,HBase开始出现无法写入现象
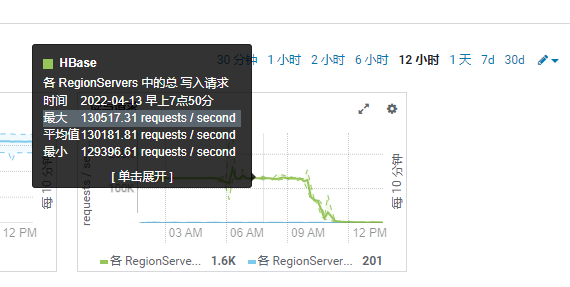
其主要原因就是hfile太多,无法compaction,导致写入被阻塞。
- 处理FileNotFound异常
https://blog.csdn.net/gavin_g_feng/article/details/118221868
对bucket-tsdb的部分region使用了assign操作。
assign操作主要是重新分配,如果一个Region下,确实丢了一个HFile(比如手动删除),通过assign后,不会再报FileNotFound异常。
而我们实际情况是Region Split后产生的引用文件。引用的hfile经过重新split后,已经没有。
所以,我们使用了assign其实是不正确的做法。应该手动删除引用文件(删除后可解决FileNotFound问题,但无法解决Region重叠问题)。
- 完成assign后,重新打开bucket-tsdb表,出现28个永久RIT。
28个永久RIT,处于opening状态。因为:split的引用文件还在,也就是说上一次的region split还没有结束,而这些Region是和其他Region有重叠。
我们做了一次:将这些永久RIT的Region从meta删除(HFile文件还在)。把这几个异常的Region进行删除。删除后重启HMaster后,表无法显示。
HMaster启动后表无法显示的主要原因是:bucket-tsdb和tsdb表依然存在着未完成的split。虽然看到了的double assign的warn日志,但主要原因是引用文件的存在。
- 经过大量时间的处理,将集群恢复正常(带病工作)
- 启动hmaster后,出现永久RIT现象,使用meta-repari修复meta
- 启动hmaster后,出现double assign警告。使用unassign操作,将它close,但一波未平一波又起,需要unassign的region太多。
- 发现tsdb表有split引用,开始将引用文件移动到其它目录,全部移走后,启动hmaster
- 启动日志发现:hbase:namespace表是未打开的,使用assign方式,将它重新分配后,再启动hmaster,正常
- 集群启动成功,可以正常写入,但region有重叠
region有重叠,是上次split遗留的结果。目前暂时还未处理region重叠问题。
HMaster内存溢出问题分析
- 大对象占用原因:StoreFileSplitter
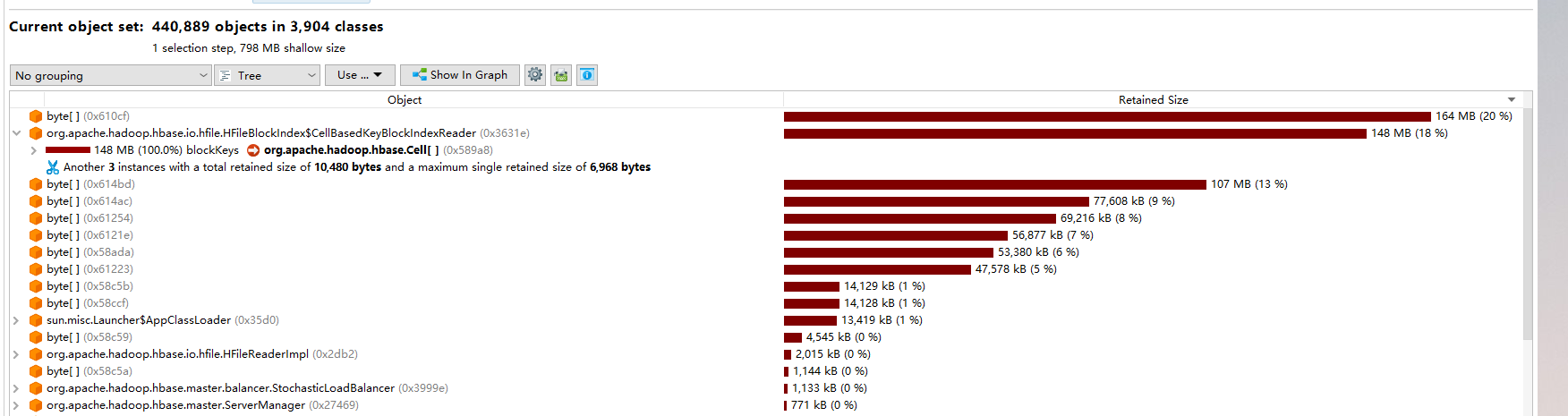
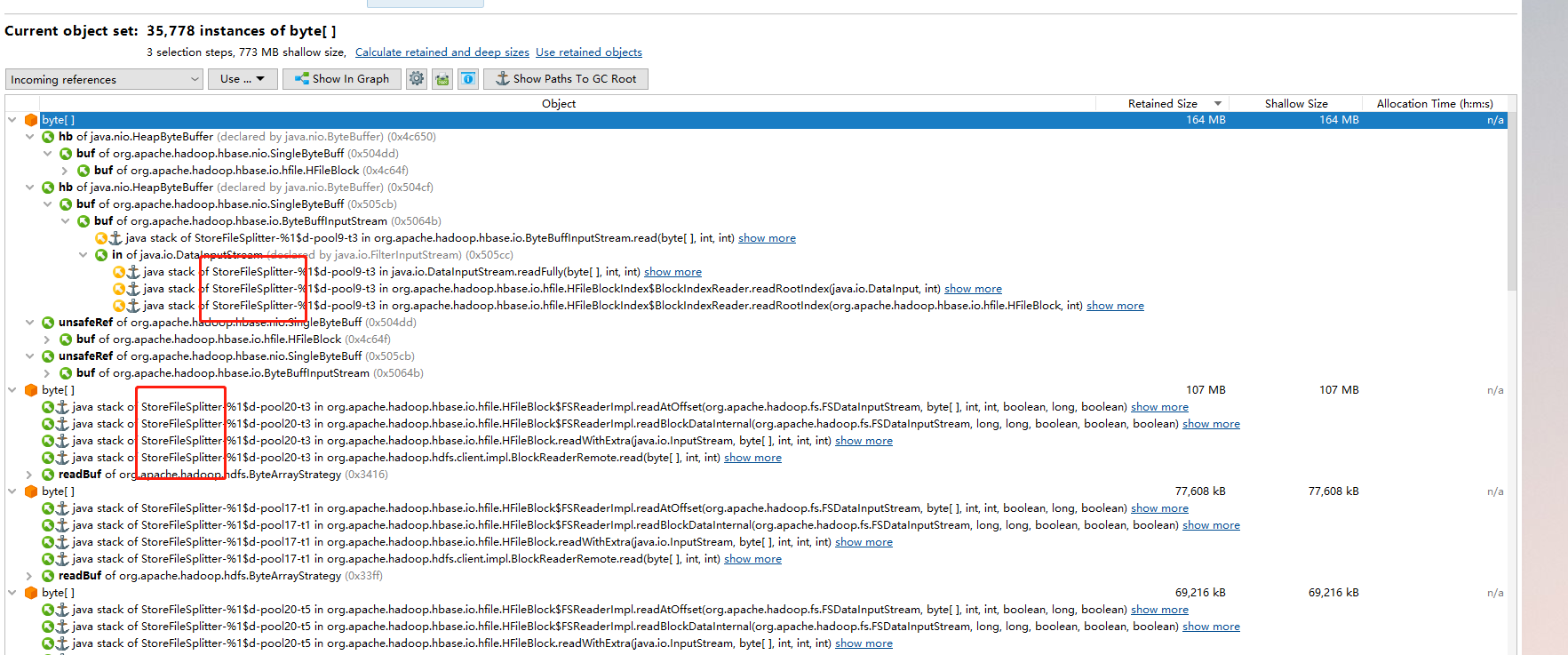
- 大量线程在执行splitter
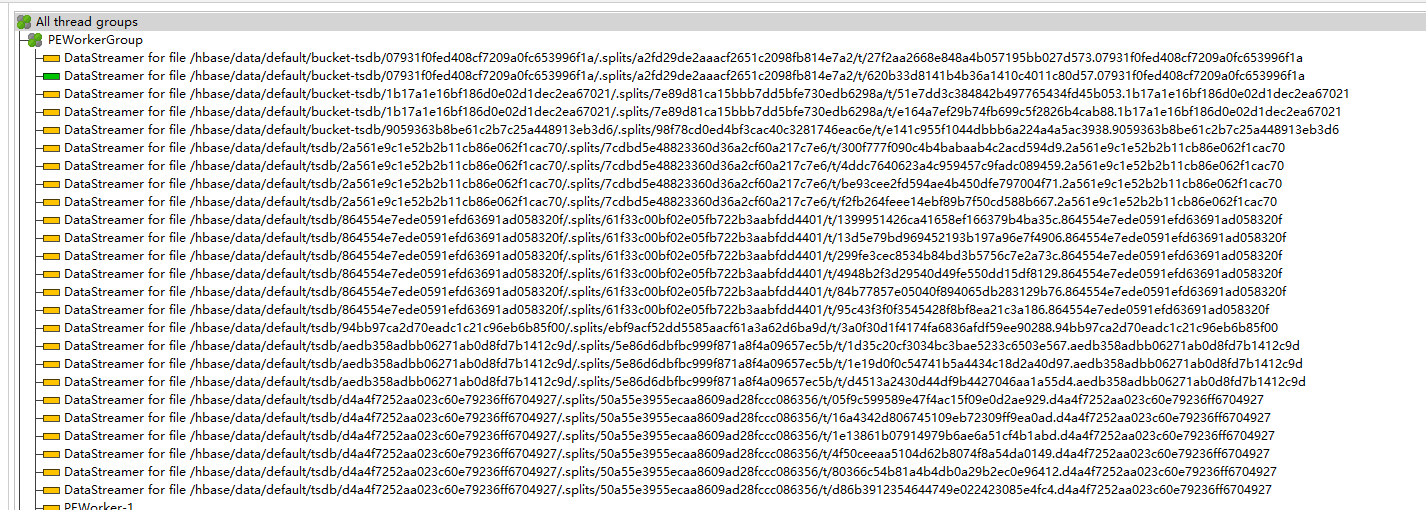
调整及后续解决方案
关于内存溢出问题调整,提升了HMaster内存到16G。该内存可以处理split请求。后续需要详细了解一下split过程,确保未来不会因为大量split,导致16G内存也不够的现象。
修复过程
- 增大HMaster内存至16G
- 移走因宕机造成的一些无效引用文件
- 停止bucket相关的表
- merge tsdb重复的region
- 搭建新集群,迁移bucket相关表
- 移走bucket-tsdb中无效的引用文件
- 从hfile将bucket-tsdb相关表恢复
- merge bucket-tsdb中重叠的region
- load 历史hfile到bucket-tsdb
- 恢复flume,向bucket-tsdb写数据
- 迁移旧集群中,flume下面的文件到新集群
- 读取flume下面的文件开始恢复历史数据
- 停止旧集群,将空闲的部分机器加入新集群
- 共用hdfs,分离部署yarn和hbase
- 全业务恢复正常
总结
- 对历史数据的大量迁移过程,使用单独集群来做,防止迁移过程中出现意想不到的错误,导致正常业务无法恢复
- 处理线上异常时,正确定位异常原因,再进行处理。
例如我们出现的FileNotFound,核心是存在无用的引用,而不是简单的assign即可
- 进行大量数据迁移时,事先全面并反复的评估风险
采坑5——当进行大批量split时,总有几个region一直处于split状态
现象
当region中,hfile大小达到近10G时,下次load,会出现大量region需要split。而split等一天还没有结束。
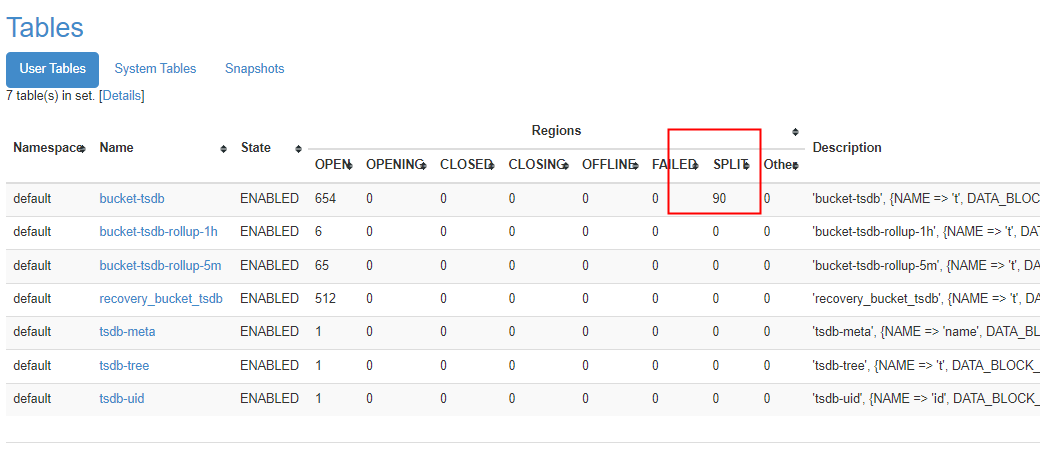
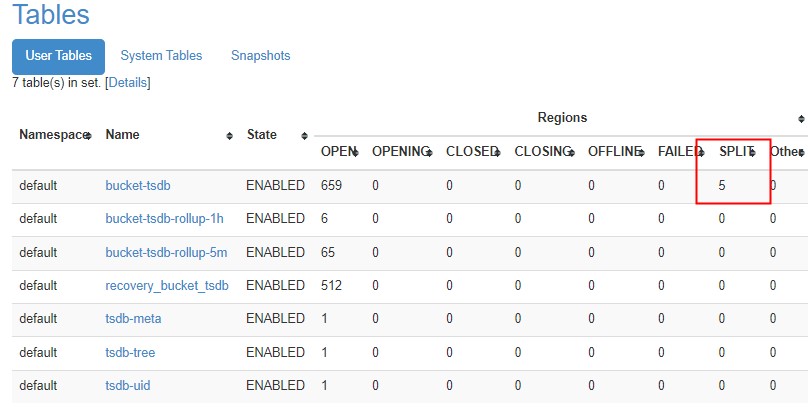
解决方案
之所以一直处于split状态,是因为,父region一直没有进行major compaction,需要等major compaction发生后才能完成。
因此,如果发现有一部分region长期处于split状态时,手动执行一下major compaction。