HBase采坑集:一、数据热点问题分析
现状
当前我们的数据是时间序列数据。由OpenTsdb写入。
OpenTsdb在HBase中设计的RowKey格式:metric_time_tagk1_tagv1…tagkn_tagvn
这种时间序列的数据,存在一个很严重的问题:数据热点。
因为metric是有限的(用户根据业务定义,大部分都相同。)
而且这种时间序列的数据有一个明显的特点就是:查询基本都是实时查询,很少涉及历史查询。
在我们当前的这个rowkey设计下,热点数据很容易产生。比如:有大量的metric被称为“温度”。故,存在某些Region是热点。在热的Region下,split时,如果metric相同,时间不同,那么会存在:一部分Region在写数据,另一部分Region啥也不干。
如下图:
这种Region是合理的,它会根据时间明确确定最新的数据只在某一个Region。
但是,对于一些冷的metric,它可能写入请求很少,也许3年时间都不进行split。那么,这样的Region,它内部的数据是合在一起的。即使查询最近一段时间的数据,也会先把历史数据过一遍。
整体Region分布情况如下:
—RegionServer-1
——Region-1:metricA_t1_xxx
——Region-2:metricA_t2_xxx
——Region-3:metricA_t3_xxx
—RegionServer-2
——Region-1:metricB_t1_xxx
——Region-2:metricC_t1_xxx
——Region-3:metricD_t1_xxx
目标
- 消除Region热点问题,即:相同的metric可以被均匀的分布在每个Region中。
- 查询最近时间范围的数据,不应该扫描历史所有时间段
- 过期3年以前的数据,并备份
策略
RowKey重新设计
opentsdb在2.2版本提供了对rowkey加盐的策略。它的加盐方式很简单,代码如下:
1 | //RowKey.prefixKeyWithSalt() |
通过代码可以看出,它的加盐策略就是:先给opentsdb配置一个SALT_WIDTH,如果SALT_WIDTH配置了,会根据:metric_tagk1_tagv1…_tagkn_tagvn来取一个hashcode,再根据配置的:SALT_BUCKETS求余。得到的值即为盐。
这种加盐之后形成的rowkey将会是下面的这种样式:例如桶大小为n。
0_metric_time_tagk_tagv
1_metric_time_tagk_tagv
……
n-1_metric_time_tagk_tagv
n_metric_time_tagk_tagv
这种rowkey的设计,可以满足我们的第一个目标:每个metric可以均匀的分布在不同的Region中。
但是当随着数据的写入,region分裂后,并不能保证分裂后的数据全部为“老”数据。即使我们增加了过期策略,也很难去备份。
随着时间的推移,它最终的结果会和我们当前的现状一样。
为了能满足目标2和3,我们期望的盐应该是这样的:bucket_time
bucket根据当前opentsdb的逻辑来实现,time取当前时间。两者合为一个rowkey前缀。故:最后的rowkey结构将会变为如下格式:
0_t1_metric_t1_tagk_tagv
1_t1_metric_t1_tagk_tagv
……
n-1_t1_metric_t1_tagk_tagv
n_t1_metric_t1_tagk_tagv
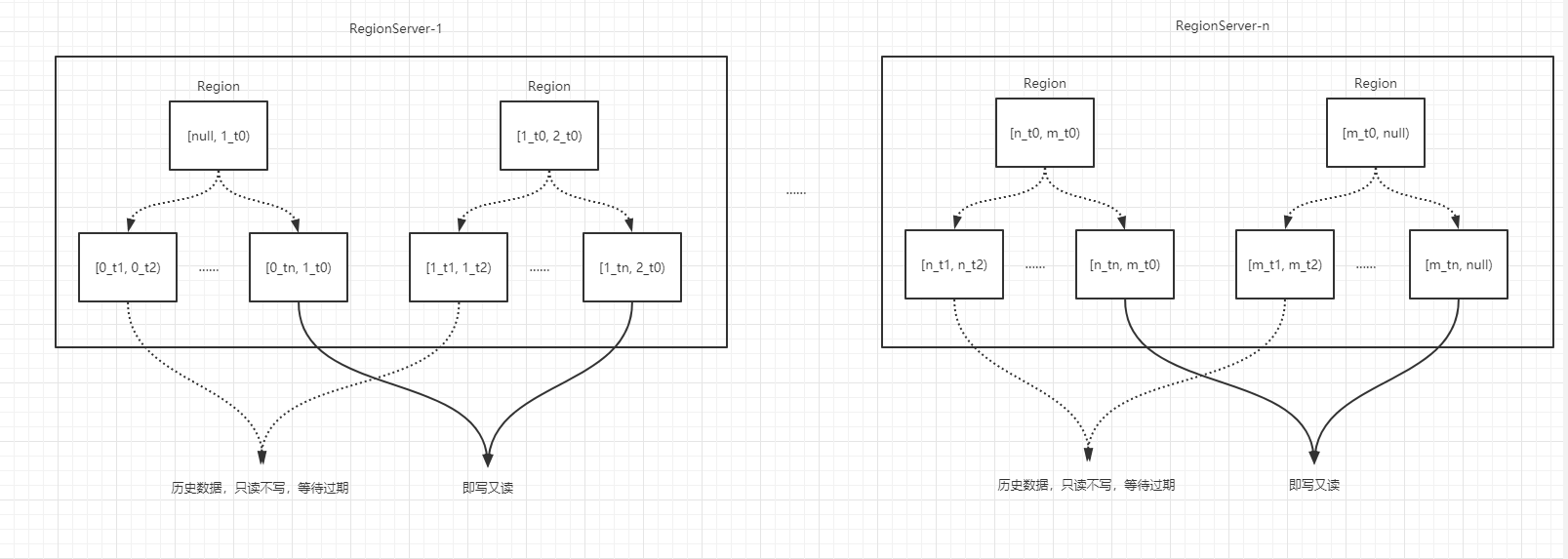
同时,我们需要自定义Region Split策略。例如:取当前Region中的start rowkey 和 end rowkey,解析rowkey prefix,bucket保持不变,split rowkey的时间为:(startTime + endTime)/2
故得到Region的rowkey范围为:[0_T1, 0_Tm),[0_Tm, 0_Tn)
在建表时,需提前规划好预分区。整体rowkey结构如下:
过期备份清除
随着时间的推移,某些Region由于时间悠久,几乎不被查询,所以需要对这些Region做备份清除。
如果将数据备份到当前HDFS下,只需要增加一个目录的引用即可,几毫秒就可以备份完成。
如果将数据备份到其他文件系统里面,只需要读取HDFS,读该Region下的所有HFile,不需要经过HBase,对HBase无影响。
备份完成后,删除该Region中的所有数据。此时:当前Region将变成一个空Region。再将和它相邻的Region做一个merge。
新结构数据导入
因为rowkey发生了改变,且要确保升级不受影响,需要将新表和老表同时运行一段时间,确保没有问题再将老表下线。
新表数据可以通过buckload方式来生成:读HBase,然后生成HFile,再从HFile生成一张新表。
(具体实现细节,参见后文)