HBase调优之二:优化压缩队列过高问题
HBase 压缩队列告警优化
线上告警现象
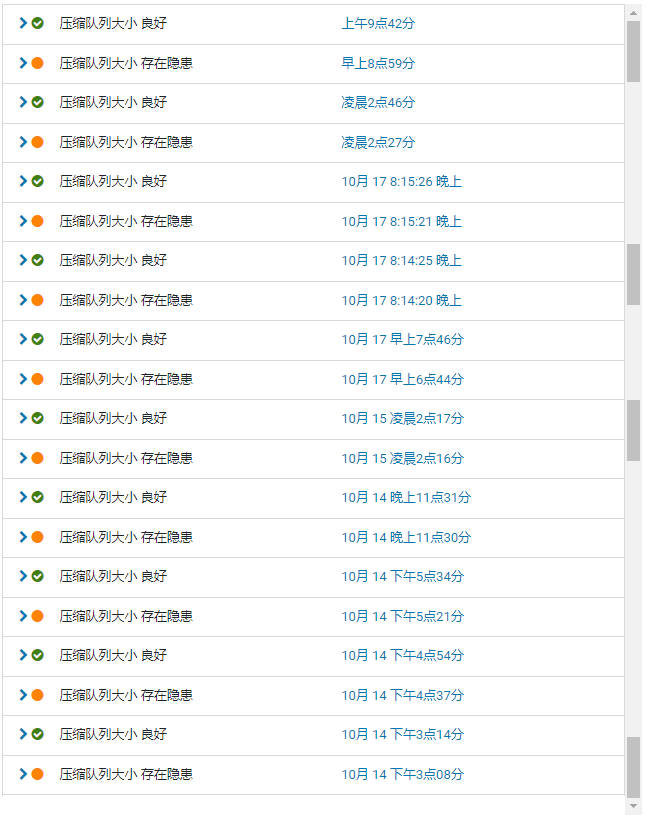
线上告警阈值大小是20,而平时的压缩队列大小能达到:50~100。
压缩队列大小怎么算
那么,这个压缩队列大小,是如何统计的呢?
查阅了很多资料,以下解释都是错误的:
- 正在进行压缩的HFile数量
- 正在压缩的HStore数量
- 等待压缩的HFile数量
这三种解释,都是错误的,也正是网上铺天盖地的这种文章,导致我在追查问题是,一直查不到。
那么,真正的大小是如何统计的呢?
下面是官方文档:http://hbase.apache.org/2.2/book.html#hbase_metrics
1 | hbase.regionserver.compactionQueueLength |
我们通过官方文档的关键词来查看它的统计规则。
在HBase源码中搜索关键词“compactionQueueLength”
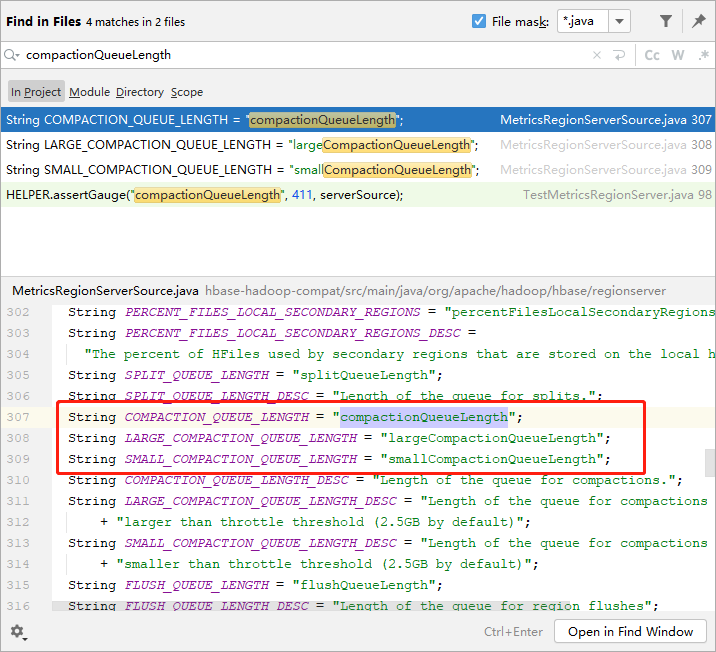
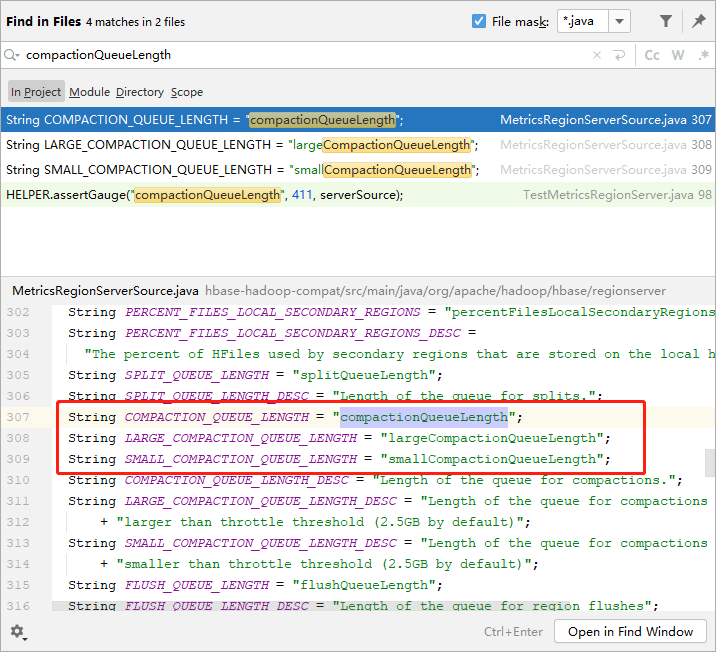
通过上一篇文章,我们知道,HBase在进行Compaction时,会通过当前需要合并的文件个数来决定使用哪个线程池去进行compaction。
HBase中有两个线程池:longThreadPool和smalThreadPool。所以,这里有3个QueueLength,一个是总和。
而我们在监控看板看到的就是总和。
进一步搜索它的引用,可以看到它的上报代码:

.jpg)
.jpg)
这两个默认值大小都是1。
也就是说,当需要进行compaction时,去申请线程,当有可用线程时,去进行compaction操作。因为核心线程数为1,所以,后来的compaction request将会被加入到队列中。
线上压缩队列比较高意味着,compaction动作很慢,而写入速度很快,导致大部分compaction request都在队列中等待。
造成压缩队列过大的原因是什么
那么是什么原因造成Compaction动作很慢呢?
当待合并的文件很大时,compaction动作会很慢。
compaction有minor compaction 和 major compaction两种,minor compaction 一般很快,除非在进行minor compaction时,同时也在做major compaction,由于限速的原因导致minor compaction持续时间长。而major compaction是进行全部文件的compaction,比较慢,持续时间久。
所以猜测,线上是发生了major compaction。
通过查询线上hbase日志,可以看到:
.jpg)
大部分时间都和告警相吻合。
也就是说,在进行 Major Compaction时,核心线程被占用,导致后面的compaction request都被阻塞。
为了确定这个猜测是否正确,我选了一个时间点,来看这一个小时内的日志是否和我们猜测一致。
.jpg)
我们看到,major compaction持续了23分钟。而同时,这个时间段,还有一个1.6G的compaction。
.jpg)
这个持续了30分钟。
6.7G的major compaction 走的时候large线程池(大于2.5G),1.6G的走的是small线程池(小于2.5G),两个大的compaction都占用了核心线程池,导致flush后的数据发生compaction request时,只能等待。因此压缩队列会持续增高。
解决问题
上面分析了引起compaction阻塞的原因。
- 待合并的文件太大,导致持续时间久
- minor compaction触发频率高(默认3个则触发)
- 核心线程池数量太小,导致其他被阻塞
了解了原因,那么,解决压缩队列大小的方法就很容易了。
HBase 2.0 提供了in memory compaction
开启in memory compaction,具体哪种策略,根据业务场景决定,我们使用的是basic方式。
从flush日志可以了解到,heap size 达到128M的时候,data size只有50M,而刷盘以后经过压缩,文件大小只有10~20M。
之所以会出现这种情况,原因上一篇也介绍过,HBase的内存结果使用的是跳跃表,跳跃表是以空间换时间的一种方式,所以,内存会被浪费。
而in memory compaction会让内存更紧凑,它会使flush频率降低,从而,会降低compaction频率
提高compaction线程池
由于大文件的compaction会阻塞小文件的compaction执行,所以,可以增大核心线程数,将核心线程数由1调整为3。
增大compaction的最小文件数阈值
默认HFile达到3个时会进行compaction,可以将3调整为5,让compaction频率降低
全局检查RegionServer是否发生热点
检查整个HBase集群上的RegionServer是否发生了热点。如果发生了热点,让RegionServer都均匀一点
调整待合并文件的最大阈值
由于我们的数据是时间序列,由opentsdb写入,大部分历史数据很少被范围查询,所以,我们让历史数据不进行compaction,从而降低单次compaction的文件总大小。目前我们由最大值更改为5G。即,超过5G的文件都不进行compaction。
调整compaction速度
上一篇文章介绍过了compaction速度控制,可以通过几个参数来调整compaction速度,让compaction尽快完成。
以上几点是对压缩队列过大的调整。我们当前调整了四项:in memory compaction,增大compaction线程池、增大最小文件数阈值、调整compaction最大文件大小。