HBase调优之一:基础原理
HBase概述
数据模型
HBase是一个数据库,它具有关系型数据库所具有的:表、行、列。
从逻辑视图来看,它是以关系型数据库中的“表”形式组织的。
从物理视图看,它是一个Map,由键值构成。
逻辑视图
逻辑视图中的几个概念:
table
表名
row
一行数据,它由一个唯一rowkey、多个column组成。
column
一列数据,它由column family 和 qualifier组成。其中,column family在创建表时指定,不能随意增减。qualifier在写数据时动态生成,可以无限扩展。
timestamp
时间戳,用于标记某个cell的版本。数据写入时自动分配一个时间戳。
cell
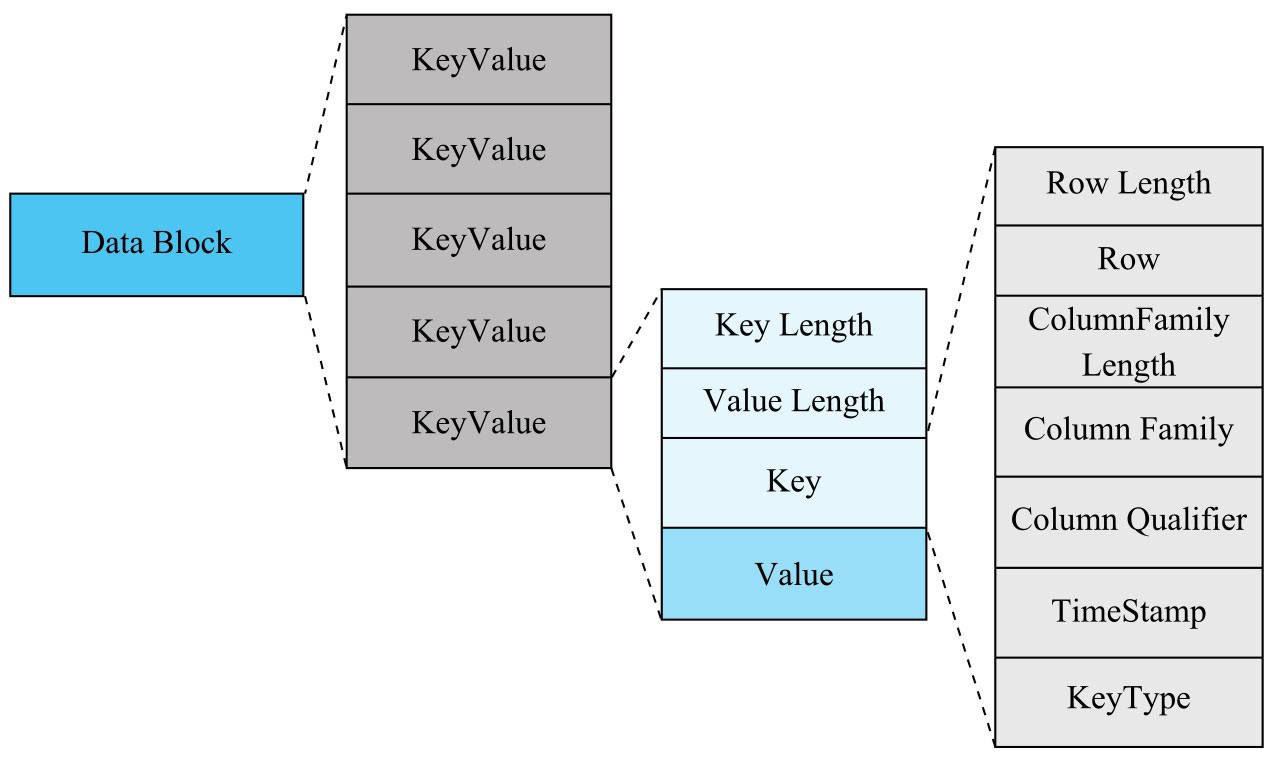
单元格,由:row、column、timestamp、type、value组成。
物理视图
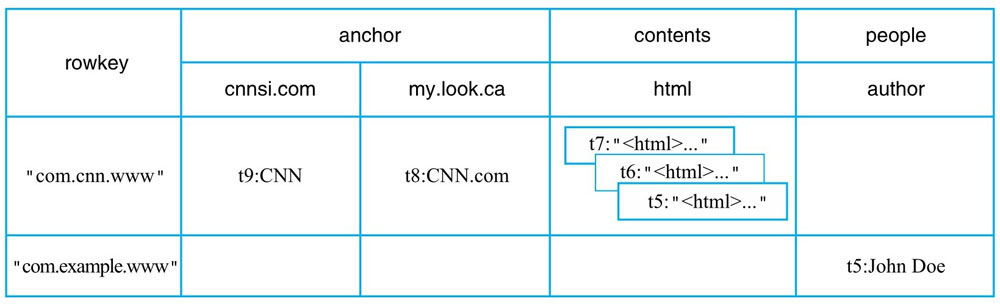
从逻辑视图看,它是一个二维表。从物理视图看,它是一个Map。
其中,Key是一个复合值,由:rowkey、column family、qualifier、type和timestamp组成。
以上面的逻辑视图举例:
行键”com.cnn.www”以及列“anchor:cnnsi.com”在HBase中实际存储结构如下:
{“com.cnn.www”,”anchor”,”cnnsi.com”,”put”,”t9”} -> “CNN”
HBase中是以列簇存储的,同一个列簇下的列存储在同一个目录下。
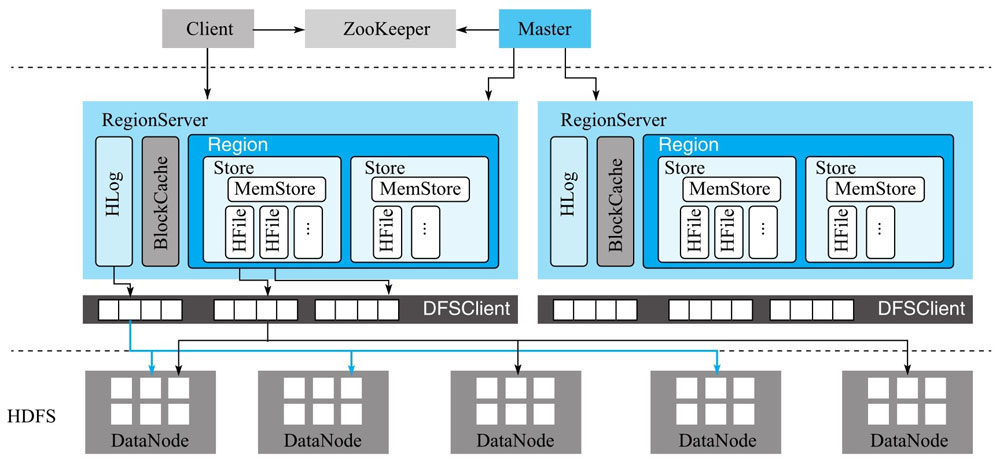
体系结构
系统特性
优势:
容量巨大
由于底层存储在HDFS,可以存储千亿行、百万列的数据规模。在这个规模下,读写性能并不会有明显的抖动。
易扩展
底层HDFS扩容简单,HBase RegionServer扩容也简单。由master来负责将Region均匀分配。
稀疏性
由于它的存储原理,为空的单元格不占任何空间。而关系型数据库会预留一定的空间。
高性能
写性能高
多版本
同一个KV可以有多个版本,在实际使用时可以根据需求选择历史版本或最新版本。
支持过期
对于需要定期清理的场景,HBase可以设置过期时间,达到自动清理。
HBase缺点:
- 不支持复杂的查询,例如group by
- 没有二级索引
- 不支持全局跨行事务
HBase基础数据结构
跳跃表
跳跃表是一种能高效实现插入、删除、查找的内存数据结构。
它的逻辑是:在链表的基础上增加多层索引。
例如:
链表中插入一个数据,先定位在哪个位置插入,再进行插入。
.jpg)
定位过程比较耗时。为了能提高定位,可以用空间换时间,提取出某些关键点,由索引层来定位。
.jpg)
这样提取一层,查找效率就能减半。如果再在第一层的基础上提取一层,查找效率又能减半。
.jpg)
这就是跳跃表。这个索引值是如何来的呢,每次插入数据时,通过“抛硬币”的方式来决定是否将它升级为索引节点。
.jpg)
.jpg)
LSM树
LSM树的名字会产生一个错误的印象,以为它和B+树、红黑树一样是一个严格的树状结构,其他它是一种存储结构(决定怎么来存储数据)。它将数据存储做了分层,内存存储和文件存储,目的是牺牲读性能来提高写性能。
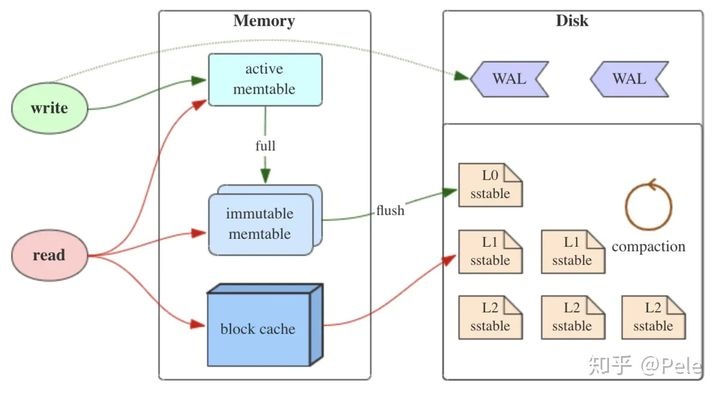
MemTable是内存中的一个数据结构,在HBase中使用的是跳跃表(ConcurrentSkipListMap)。
Immutable MemTable,是MemTable达到一定大小后转换来的,它是不会再接收写请求的,是要等待flush到磁盘的一个中间状态。在HBase中,也是一个跳跃表。(后面会介绍)
SSTable(Sorted String Table),是LSM树在磁盘中的数据结构,HBase中是KV数据结构。
RegionServer的核心
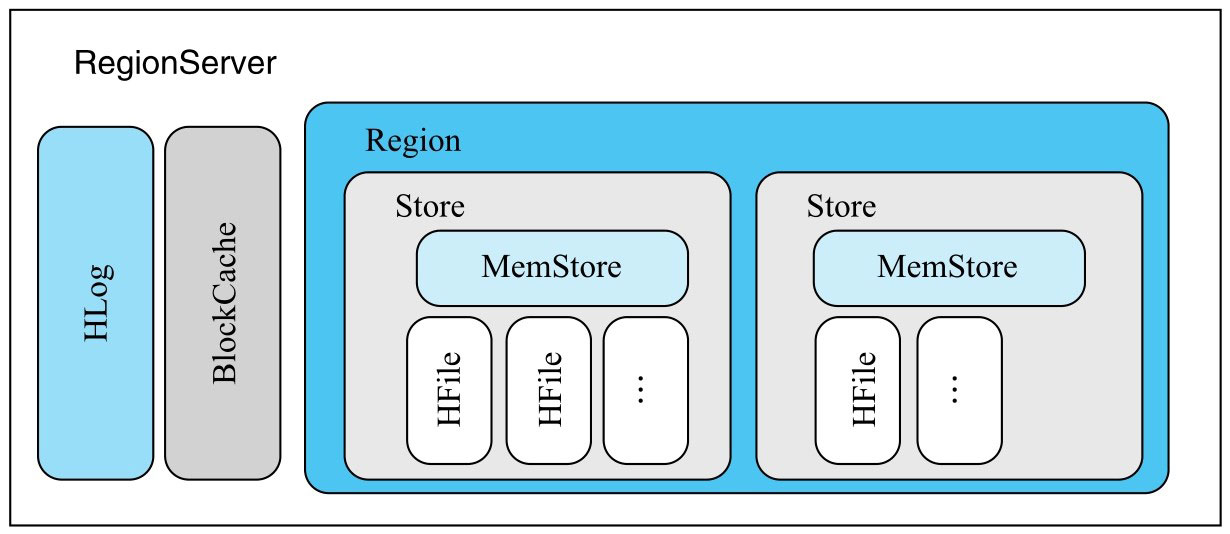
RegionServer是HBase系统响应用户读写请求的工作节点组件。
HLog
HBase中故障恢复和主从复制都是基于HLog实现。写入数据时,是先写入HLog,再写入MemStore。
默认情况下,每个RegionServer拥有一个HLog。如果HLog遇到瓶颈,可以开启多个HLog。
配置方式:
1 | # 开启多wal功能,目前线上是开启的 |
HLog文件并不会永久存储,它在某个时间会失效,最终被删除。

HBase后台有一个线程,每隔一小时会进行日志滚动。它的内部逻辑是:停止当前日志文件的写入,创建一个新的日志文件接收数据。滚动时间可由参数配置:
1 | hbase.regionserver.logroll.period = 1 |
当写入的数据从MemStore刷写到磁盘以后,对应的日志数据会失效。当某个HLog文件中的数据全部落盘以后,这个HLog就会失效。
HBase后台还有一个线程,去检查失效的log文件,去把它们删除。当失效超过某个时间,则删除。
1 | hbase.master.logcleaner.ttl = 1分钟 |
BlockCache
为了避免读数据时存在大量的IO操作,HBase提供了一个缓存机制。客户端读取某个Block,首先会检查该Block是否存在于BlockCache中,如果在,就直接从BlockCache中取,如果不在,则从HFile中加载,加载完成后,放入BlockCache中。
Block是HBase中最小的数据读取单元,在HFile中有一个叫DataBlock的,主要用来存放数据。
MemStore
HBase中的一张表会被水平切分成多个Region,每个Region负责自己区域的数据读写请求。切分的目的主要是为了并发写入。
数据写入HBase时,先写入HLog,再写入MemStore,当MemStore中的数据大小超过阈值之后就会刷写到磁盘,生成一个新的HFile文件。
MemStore的内部结构是一个跳跃表。继承了ConcurrentSkipListMap。它内部有两个ConcurrentSkipListMap,当MapA写满后,会创建一个MapB来接收新的请求,而MapA则刷写到磁盘中去。刷写完成以后MapA继续可用。
HFIle
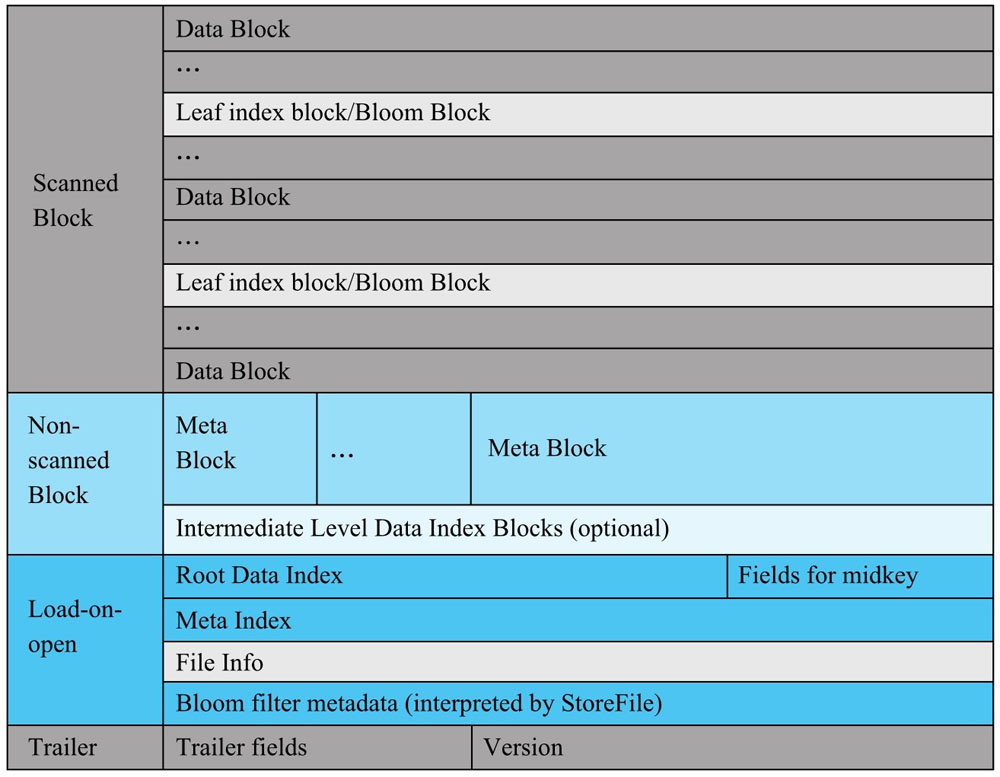
Scanned Block部分
这部分由3种数据块组成。Data Block,Leaf Index Block和Bloom Block。
Data Block中存放的是KV,leaf index block是存储索引树的叶子节点数据。Bloom Block存储的是过滤器相关的数据。
扫描时,这三部分都会被读取。
Non-Scanned Block
扫描时,不会被读取。主要包含:meta block 和 intermediate level data index blocks
Load-on-open
RegionServer打开HFile时直接加载到内存,包括FileInfo、MetaBlock、RootDataIndex和MetaIndexBlock
Trailer部分
记录HFIle版本信息,以及各部分的偏移值和寻址信息
MemStore Flush
Flush触发时机:
MemStore级别
当Region中的任何一个MemStore大小达到上限(hbase.hregion.memstore.flush.size)
Region级别
当Region中所有MemStore的大小总和达到了上限
hbase.hregion.memstore.block.multiplier * hbase.hregion.memstore.flush.size
RegionServer级别
当RegionServer中MemStore的大小总和超过低水位阈值
hbase.regionserver.global.memstore.size.lower.limit * hbase.regionserver.global.memstore.size
当一个RegionServer中HLog数量达到上限
hbase.regionserver.maxlogs
定期触发MemStore
默认一小时,确保MemStore不会长时间没有持久化
手动执行flush
执行流程:
prepare阶段:遍历MemStore,将MemStore中当前数据集做一个快照,然后再建一个新的ConcurrentSkipListMap用来接收写入的新数据。
flush阶段:将prepare阶段生成的快照持久化到临时文件,存放在./tmp目录下
commit阶段:将flush阶段生成的临时文件移动到指定的ColumnFamily目录下
MemStore Flush操作不会对业务产生影响。如果是RegionServer级别的flush,会阻塞RegionServer上写入数据。
Compaction实现原理
HBase中小文件数量过多,会引起读取效率降低,为了保证读取效率,HBase提供了一种机制叫:Compaction。
Compaction是从一个Region的一个Store中选择部分HFile文件进行合并。合并的原理是:先从这些待合并的数据文件中依次读出KeyValue,再由小到大排序(归并)后写入一个新的文件。
HBase会根据合并规模将Compaction分为两类:Minor Compaction 和 Major Compaction。
Minor Compaction
选择部分小的、相邻的HFile,将他们合并为一个更大的HFile。
Major Compaction
将一个Store中所有的HFile合并成一个HFile。这个过程会清理三类无意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。
不合并和合并后的查询对比图:
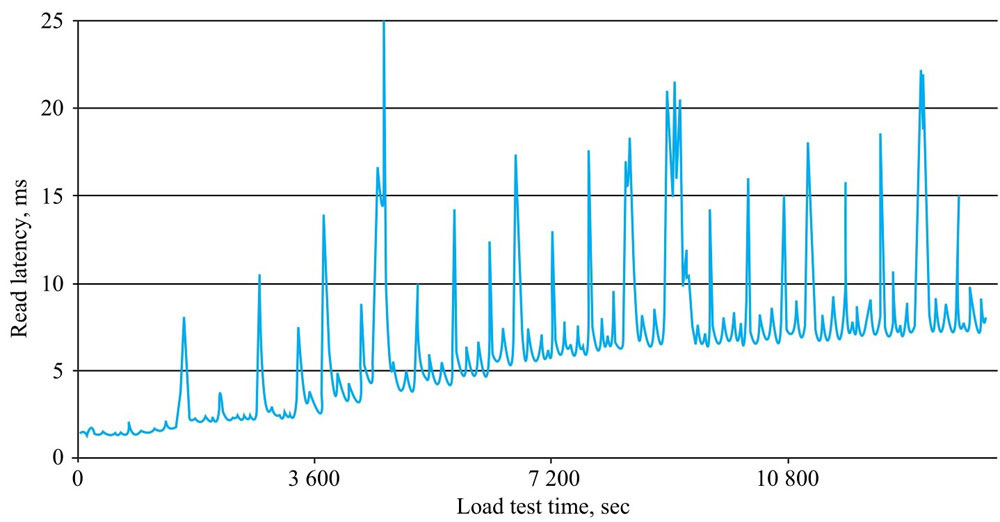
Compaction在执行过程中有个比较明显的缺点:
Compaction操作重写文件会带来更大的带宽压力和短时间的IO压力。因为需要从HDFS其他节点去读取数据。
Compaction操作流程
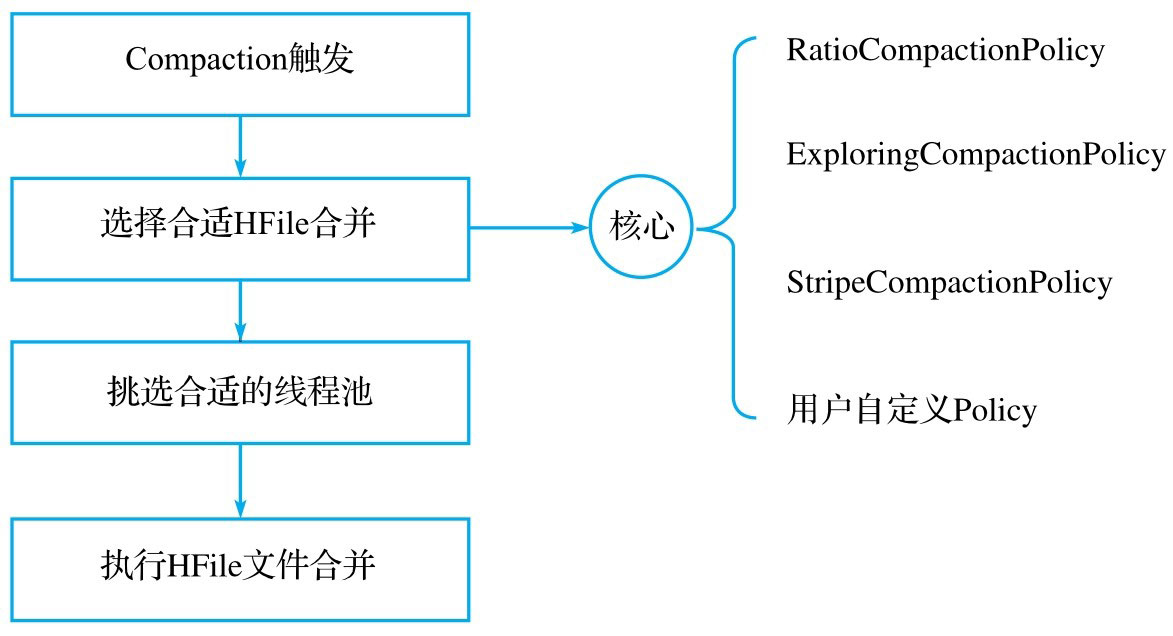
Compaction触发条件
Compaction触发条件有三种,任意一种满足,就进行Compaction。
MemStore Flush
MemStore Flush会产生HFile(每次Flush都是一个新的HFile),每次执行完flush操作后都会对当前Store(Region)的文件数进行判断,当Store中的文件数大于hbase.store.compactionThreshold,就会触发Compaction。默认3个。Compaction都是以Store为单位进行的,由于我们每个表都有一个列簇,所以,基本可以理解为,Compaction是以某个Region为单位进行的。
后台线程周期性检查
RegionServer在后台有一个叫CompactionChecker的线程,会定期检查每个Store(Region)是否需要进行Compaction。检查周期:
hbase.server.thread.wakefrequency(10s) * hbase.server.compactchecker.interval.multiplier(1000)
先检查Store中文件数是否满足minor compaction的阈值,满足就进行minoer compaction。如果不满足,再检查Major Compaction条件(HFile文件最早更新时间是否早于hbase.hregion.majorcompaction)。
手动触发
HFile选择策略
HBase在进行compaction前,需要先进行筛选。基本流程如下:
排除当前正在执行Compaction的文件以及比这些文件更新的所有文件
排除某些过大的文件。
配置项:hbase.hstore.compaction.max.size,默认:Long.MAX_VALUE。意味着,所有过大的文件都会进行compaction。过大会带来更大的IO消耗
经过排除,判断留下来的候选文件是否满足Major Compaction条件。满足任一条件:
- 用户强制执行Major Compaction
- 长时间没有执行Major Compaction,且候选文件数小于:hbase.hstore.compaction.max(10)
- Store中包含reference文件。reference文件是region分裂产生的临时文件
如果major compaction满足了条件,则要进行Major Compaction,当前Store中的所有HFile都会被合并。如果不满足,则进行minor compaction。minor compaction有两种选择策略,分别是:RatioBasedCompactionPolicy和ExploringCompactionPolicy。后者是在前者的基础上做了一点优化。
RatioBasedCompactionPolicy
从老到新逐一扫描所有候选文件,满足其中一个便停止扫描
- 当前文件大小 < 比当前文件新的所有文件大小总和 * ratio,其中,ratio是一个可变的比例,高峰期:1.2,非高峰期:5。高峰期和非高峰期可由参数配置,高峰期区间:[hbase.offpeak.start.hour, hbase.offpeak.end.hour]
- 当前所剩候选文件 <= hbase.store.compaction.min(3)
停止扫描以后,待合并的文件就选择出来了:当前扫描文件以及比它更新的所有文件。
ExploringCompactionPolicy
该策略和上面的相同,不同的是,Ratio策略在找到一个合适的文件集合之后就停止扫描,而Exploring策略会记录所有合适的文件集合,并在这些文件集合中寻找最优解。最优解是:待合并文件数最多或者待合并文件数相同的情况下文件较小。
合并HFile
- 分别读取待合并的HFile文件的KeyValue,进行归并排序后,写入./tmp目录下的临时文件中
- 将临时文件移动到对应的Store目录下
- 将Compaction的输入文件路径和输出文件路径封装为KV写入HLog,并打上Compaction。
- 将对应Store目录下的Compaction输入文件全部删除。
Compaction注意事项
Compaction执行过程会消耗带宽和IO,如果不对它进行限制,会出现读写延迟。所以,HBase提供了几个对Compaction优化项。
Limit Compaction Speed
该优化项通过感知Compaction的压力情况自动调节Compaction吞吐量。在 压力大的时候降低合并吞吐量,压力小的时候增加合并吞吐量。工作原理:
- 在正常情况下,用户需要设置吞吐量下限参数“hbase.hstore.compaction.throughput.lower.bound”(10MB/s)和上限参数”hbase.hstore.compaction.throughput.higher.bound”(20MB/s)。而HBase实际工作在吞吐量为:lower + (higher - lower) * ration的情况下。其中ratio是一个(0,1)的小数,它由当前Store中待参与Compaction的HFile数量决定,数量越多,ratio越小,反之越大。
- 如果当前Store中HFile的数量太多,并且超过了参数blockingFileCount时,此时所有写请求都会被阻塞以等待Compaction完成,配置项:hbase.hstore.blockingStoreFiles,默认16。它会阻塞MemStore刷写动作,但不会阻塞写入请求,如果在它还没有完成Compaction时写入了大量的数据,就会导致MemStore写满,最终导致HBase崩溃。
Compaction BandWidth LImit
该优化项也有两个参数:compactBwLimit 和 numOfFilesDisableCompactLimit
compactBwLimit
一次Compaction的最大带宽使用量,如果Compaction所使用的贷款高于该值,就会强制其sleep一段时间
numOfFilesDisableCompactLimit
在写请求非常大的情况下,限制compaction贷款的使用量必然会导致HFile堆积,进而影响读请求响应延时,因此该值的意图是:一旦Store中HFile数量超过该设定值,贷款限制就会失效。
HBase写入异常分析
情况一:MemStore占用内存大小超过设定阈值导致阻塞
现象:整个集群写入阻塞,业务反馈写入请求大量异常
写入异常定位:在RegionServer的日志中搜索“Blocking updates on”,如果能搜到下面的日志,说明写入阻塞是由于RegionServer的MemStore所占内存大小已经超过JVM内存大小的上限比例(hbase.region.global.memstore.size)。
Blocking updates on ***: the global memstore size *** is >= than blocking *** size
导致该异常发生的主要原因是:HFile数量太多导致flush阻塞(上面提到过),可以通过搜索“too many store files”来判断是否是由于HFile引起的阻塞。
判断是否发生阻塞的一种方法:在web ui上查询Num StoreFiles值,和当前RegionServer中的Num.Stores值。两者相处,如果大于blockingStoreFiles,肯定会阻塞。
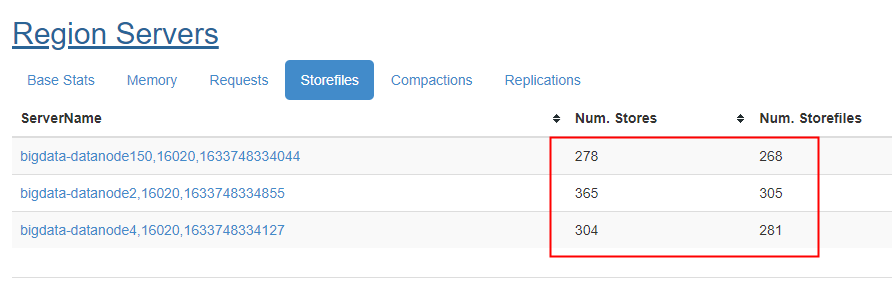
那么核心问题是,为什么HFile数量会增长这么快。理论上如果Compaction的相关参数配置合理,HFile的数量会在一个正常范围上下波动。别人的案例是,表压缩未采用snappy压缩,而是使用PREFIX_TREE编码,该编码格式在某些场景下会导致执行Compaction的线程阻塞,进而消耗compaction线程池中所有工作线程,从而导致其他表的compaction请求只能在队列中排队。
情况二:RegionServer Active Handler资源被耗尽导致写入阻塞
如果情况一下未检索到HFile数量过多问题,那么有可能是RegionServer中Active Handler被耗尽。
hbase.regionserver.handler.count可以配置它的数量,默认值是30。正常写入情况下,handler在处理完客户端请求后就会立马释放,只有在写请求延迟比较大的情况下,才会耗尽。