Spark之五:Spark运行机制
核心概念
在介绍集群模式前,先来再回顾一下spark中的几个核心概念
driver
dirver是spark应用程序的起点,它是spark应用程序的执行控制器,同时也维护者spark集群中所有的状态(执行节点的状态和任务的进度)。它必须与集群管理器对接,以便实际获得资源并启动spark应用。该driver可以是集群中的某个节点,也可以是你自己的一个计算机(可以向集群提交任务)。
driver进程主要负责三件事:
- 运行main程序
- 将spark任务分发到executor,并监控每个executor的运行状态
- 向用户反馈spark应用的运行过程
executor
executor是执行dirver分配的任务的进程(jvm),它承担的责任是:运行dirver分配的任务、向driver汇报执行结果(成功或失败)。每个spark应用都有自己独立的一套executor,它们不能再被别的spark应用使用。
partition
spark任务能够并行执行,并不是说我们在启动时分配了n个executor,而是partition的个数。spark将操作的数据分解成为块,这些数据块称为partition。例如读取一张10万行的表,如果设置的partition个数是1,即只有一个数据块,那么即使你启动了千个executor,也只有一个executor来读取这十万行的表。因此,partition是真正决定spark任务并行度的关键因素。spark的最大并行度是:number executor * executor core。如果partitions > 最大并行度,那么有一部分partition需要等其他partition结束才能开始执行。
cluster manager
driver和executor并不是凭空出现的,它们是由cluster manager提供而来。cluster manager主要的责任是维护运行你的spark应用的机器。它本身也是一个主从架构,只是它们与实际的物理计算机绑定。而spark应用中的dirver、executor只是从这些物理机上启动了一个进程(jvm)而已。例如我们比较熟悉的yarn,就是一个cluster manager。
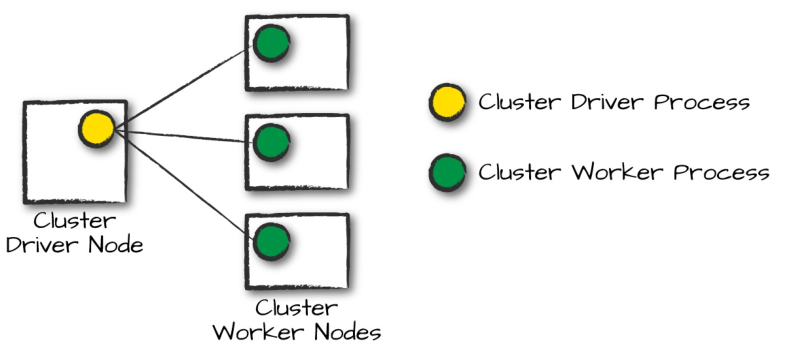
图中,左边是集群中的一个driver节点(如果是yarn集群,通常是master节点),右边是集群中的多个worker节点(如果是yarn集群,通常是slaves节点)。圆圈代表每个driver process和worker process,这儿不要和spark的dirver和executor混淆,这儿的dirver process在yarn中,就是ResourceManager,worker process在yarn中是NodeManager。
spark目前可以运行在以下几种cluster manager中
- standalone
- mesos
- yarn
- Kubernetes
可以根据自己的需求来决定运行在哪个cluster manager中。通常我们运行在yarn中。
Spark运行模式
不管是运行在哪种cluster manager中,运行spark应用通常有三种模式
- cluster mode
- client mode
- local mode
cluster mode
cluster mode是工作中最常用的一种模式,用户将自己已经编译好的jar提交到cluster manager后,cluster manager会在内部寻找worker节点来运行spark应用。
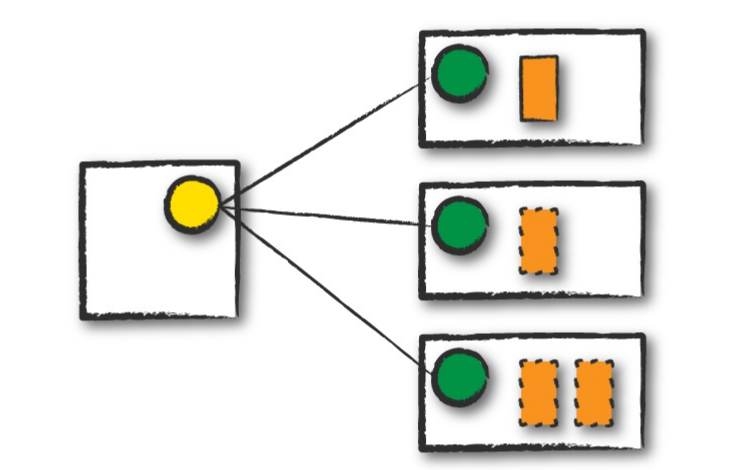
client mode
client mode与cluster mode类似,不同点在于,driver process是在提交spark应用程序的节点上启动的,也就是说,客户端节点来维护driver process,cluster manager来维护executor process。
需要明确一点的是,任意计算机都可以提交spark应用,前提是它们可以通过网络访问到集群。如果你提交spark应用的计算机是集群内部的一个节点,则可以使用client mode,如果你提交spark应用程序的计算机是集群外的,比如你自己的笔记本,推荐使用cluster mode。因为client mode会有大量网络I/O,效率不会很高。
local mode
local mode模式就是我们本地模式,dirver process、executor process都由本地计算机启动。比如我们写完spark任务后,直接run进行测试。一般用于学习和测试时,在生产上不适用。
Spark应用的生命周期
我们通过一个demo来说明spark的生命周期。假设我们需要将spark应用提交到yarn上,yarn集群一共4个节点,一个ResourceManager,三个NodeManager。
客户端提交spark应用
第一步,将你已经编译好的spark应用提交至yarn集群。客户端可以任意选择,假如是你本地计算机,使用cluster mode提交。该步骤表示,我们告诉yarn集群,我们需要一个节点(资源)来运行spark driver process。假如yarn集群接受了我们的请求,并将spark driver process放在了某个节点上执行,此时我们的客户端便可以断开与集群的连接,集群依旧保持运行。如下图:

你也可以不用断开与集群的连接,集群会间隔的发送应用的app_id过来。
分发任务
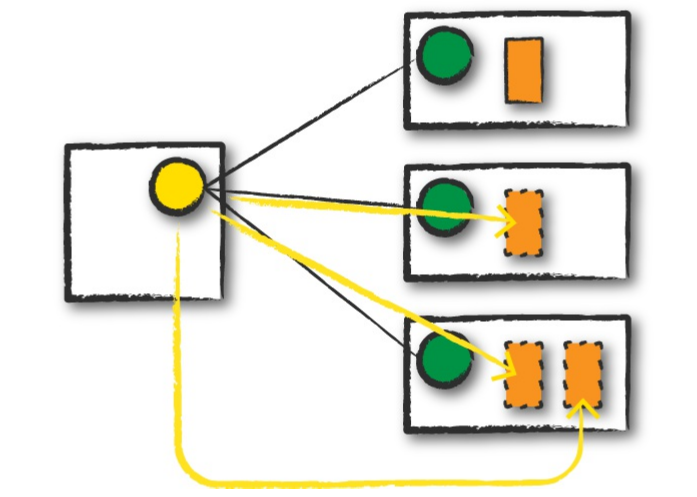
提交完spark应用后,此时,整个spark程序已经在集群上了。driver会根据程序中设定的参数或提交时指定的参数,来向cluster manager申请资源去启动executor来运行task,cluster manager启动executor后,会将该executor的位置(哪个节点)发送给driver。如下图:
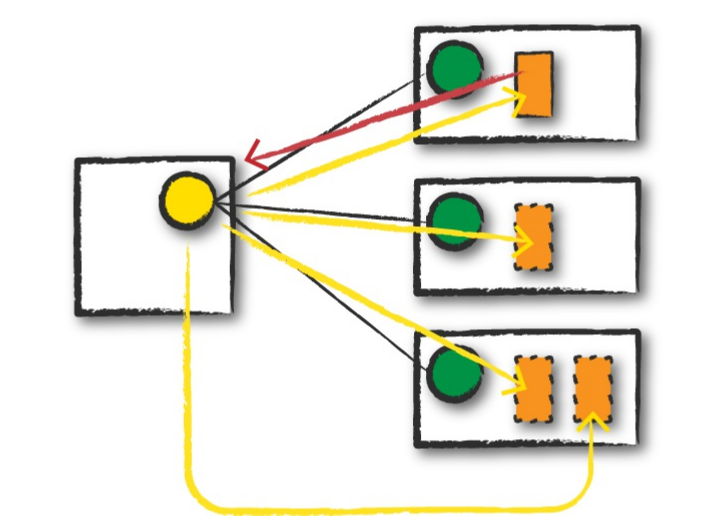
说明:
- 黄色圆圈代表ResourceManager
- 绿色圆圈代表NodeManager
- 橙色实线方框代表spark driver process
- 橙色虚线方框代表spark executor process
- 红色箭头代表向ResourceManager申请资源,启动executor
- 黄色箭头代表在NodeManager中启动executor
执行任务
任务分发完成之后,集群开始执行spark任务。dirver和executor会相互通信,spark driver process会将任务调度到executor process,executor process开始执行task,并将执行task的进度分发到driver process。期中,每个driver process、executor process实际上就是一个jvm。
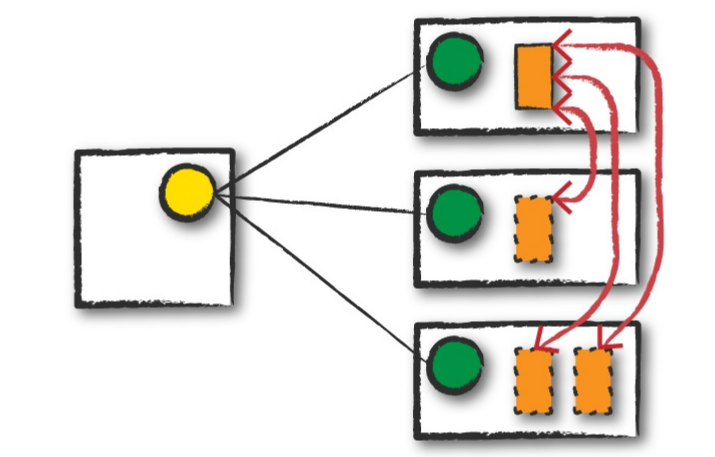
执行结束
spark任务执行结束,不管是成功还是失败,ResourceManager会去关闭执行spark程序的executor。如下图:
至此,整个spark任务的基本过程已介绍完,下面我们详细介绍一下它的详细执行过程。
Spark应用的生命周期2
前面介绍的是spark应用运行的一个生命周期,下面专注介绍一下spark应用内部的一些知识。
SparkSession
每一个spark应用程序的第一步是创建SparkSession。SparkSession是整个spark应用的生命周期,创建SparkSession推荐使用SparkSession.builder来创建,因为它可以更健壮的实例化sparkContext和sqlContext。
SparkSession、SparkContext、SqlContext区别
SparkSession是用来定义整个spark应用的执行环境,由SparkSession可以创建出SparkContext和SqlContext。SparkContext是spark上下文,它在spark应用中始终只有一个,如果要启动多个SparkContext,需要先停止掉之前创建的。SqlContext是用来执行SQL的上下文。SparkContext操作的是底层的RDD,SqlContext操作的是高层的SQL语句,其底层还是转换为RDD形式。
Spark Job
一般情况下,一个action对应一个spark job,每个action都会返回结果。每个job分为几个stage,一般stage的划分是以shuffer来划分。
stage
stage表示spark任务的执行阶段,意味着,在当前阶段,spark集群可以同时进行执行,一个stage可以被分成多个task来执行。某个stage执行完成之后,进入下一个stage。为了更方便理解,下面是以wordcount为例,stage的物理执行过程图。
1 | def main(args: Array[String]): Unit = { |
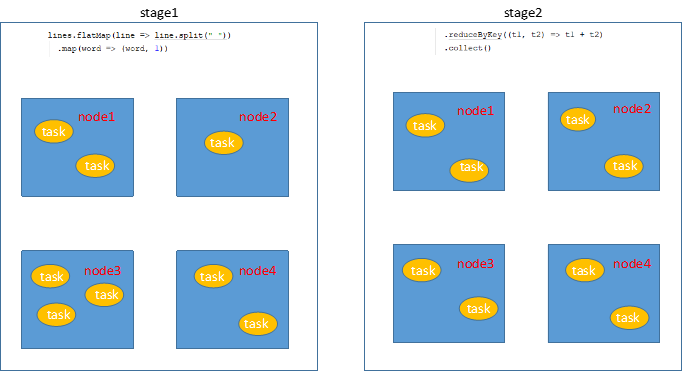
注意:多个stage并行执行时,执行顺序是随机的。例如rdd1和rdd2join时,生成rdd1的stage和生成rdd2的stage是随机来执行的。
task
task是实际来执行spark的最小单位,一般分区的数量决定task的数量。一个分区一个task。将任务分为更多的分区意味着会有更大的并行度,调大分区个数虽然不是万能的,但是也是某些时候进行性能调优的一个重要依据。